深度学习中一个核心问题是如何公平地量化每个训练样本对模型性能的贡献 ,Data Shapley是其中一种方案。但是原始的Shapley
值的计算需要重复训练,对于大规模数据集计算 impractical。In-run Data Shapley提供了一种一次训练即可得到所有样本
Shapley 值的方法。
原始 Data Shapley#
将训练集 D = { z 1 , z 2 , . . . , z n } D = \{z_1, z_2, ..., z_n\} D = { z 1 , z 2 , ... , z n } n n n A A A V ( S ) V(S) V ( S ) S ⊆ D S \subseteq D S ⊆ D z i z_i z i Data Shapley Value 定义为所有可能子集的加权边际贡献之和:
ϕ i = 1 n ∑ k = 0 n − 1 ( n − 1 k ) − 1 ∑ S ⊆ D ∖ { i } ∣ S ∣ = k [ V ( S ∪ { i } ) − V ( S ) ] \phi_i = \frac{1}{n} \sum_{k=0}^{n-1} \binom{n-1}{k}^{-1} \sum_{\substack{S \subseteq D \setminus \{i\} \\ |S| = k}} \big[ V(S \cup \{i\}) - V(S) \big] ϕ i = n 1 k = 0 ∑ n − 1 ( k n − 1 ) − 1 S ⊆ D ∖ { i } ∣ S ∣ = k ∑ [ V ( S ∪ { i }) − V ( S ) ] 这等价于:
ϕ i = 1 n ! ∑ π ∈ Π [ V ( P i π ∪ { i } ) − V ( P i π ) ] \phi_i = \frac{1}{n!} \sum_{\pi \in \Pi} \big[ V(P_i^\pi \cup \{i\}) - V(P_i^\pi) \big] ϕ i = n ! 1 π ∈ Π ∑ [ V ( P i π ∪ { i }) − V ( P i π ) ] 其中 P i π P_i^\pi P i π π \pi π i i i
Data Shapley 是唯一同时满足以下性质的估值方法:
公理 含义 Null Player(零贡献) 如果一个样本加入任何子集都不改变模型性能,其 Shapley 值为 0 Symmetry(对称性) 如果两个样本对所有子集的边际贡献完全相同,它们的 Shapley 值相等 Additivity(可加性) 如果性能由两个指标 V + W V+W V + W ϕ i ( V + W ) = ϕ i ( V ) + ϕ i ( W ) \phi_i(V+W) = \phi_i(V) + \phi_i(W) ϕ i ( V + W ) = ϕ i ( V ) + ϕ i ( W ) Efficiency(效率) 所有样本的 Shapley 值之和等于 V ( D ) − V ( ∅ ) V(D) - V(\emptyset) V ( D ) − V ( ∅ )
显然,如果要精确计算规模为n的数据集需要对 2 n 2^n 2 n 计算复杂度为 O ( 2 n ) O(2^n) O ( 2 n ) ,对大规模数据集完全不可行。
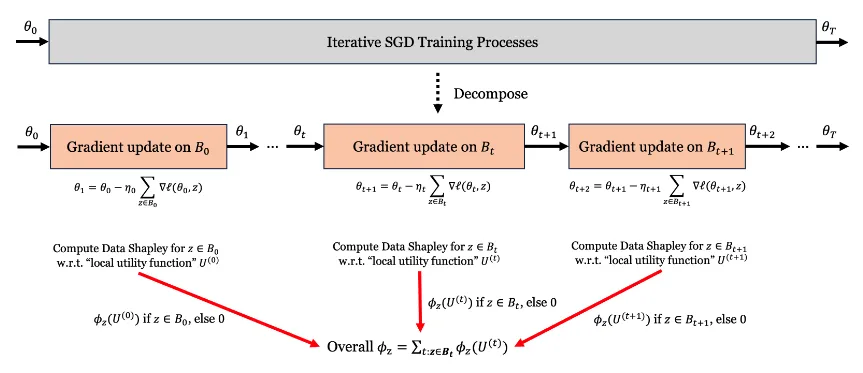
In-Run Data Shapley#
论文定义局部效用函数:
U ( t ) ( S ) = ℓ ( w ~ t + 1 ( S ) , z val ) − ℓ ( w t , z val ) U^{(t)}(S) = \ell(\tilde{w}_{t+1}(S), z^{\text{val}}) - \ell(w_t, z^{\text{val}}) U ( t ) ( S ) = ℓ ( w ~ t + 1 ( S ) , z val ) − ℓ ( w t , z val ) 其中 w ~ t + 1 ( S ) = w t − η t ∑ z ∈ S ∇ ℓ ( w t , z ) \tilde{w}_{t+1}(S) = w_t - \eta_t \sum_{z \in S} \nabla \ell(w_t, z) w ~ t + 1 ( S ) = w t − η t ∑ z ∈ S ∇ ℓ ( w t , z ) S ⊆ batch S \subseteq \text{batch} S ⊆ batch t t t S S S
将上式 U ( t ) ( S ) U^{(t)}(S) U ( t ) ( S ) ℓ ( w , z val ) \ell(w, z^{\text{val}}) ℓ ( w , z val ) w w w w t w_t w t
f ( w ) = f ( w t ) + ∇ f ( w t ) T ( w − w t ) + 1 2 ( w − w t ) T ∇ 2 f ( w t ) ( w − w t ) + O ( ∥ w − w t ∥ 3 ) f(w) = f(w_t) + \nabla f(w_t)^T (w - w_t) + \frac{1}{2} (w - w_t)^T \nabla^2 f(w_t) (w - w_t) + O(\|w - w_t\|^3) f ( w ) = f ( w t ) + ∇ f ( w t ) T ( w − w t ) + 2 1 ( w − w t ) T ∇ 2 f ( w t ) ( w − w t ) + O ( ∥ w − w t ∥ 3 )
可得
U ( t ) ( S ) = − η t ∑ z ∈ S ∇ ℓ ( w t , z val ) ⋅ ∇ ℓ ( w t , z ) ⏟ U 1 ( S ) + 1 2 η t 2 ( ∑ z ∈ S ∇ ℓ ( w t , z ) ) T H t ( ∑ z ∈ S ∇ ℓ ( w t , z ) ) ⏟ U 2 ( S ) + O ( η t 3 ) U^{(t)}(S) = \underbrace{-\eta_t \sum_{z \in S} \nabla \ell(w_t, z^{\text{val}}) \cdot \nabla \ell(w_t, z)}_{U_1(S)} + \frac{1}{2} \underbrace{\eta_t^2 \left(\sum_{z \in S} \nabla \ell(w_t, z)\right)^T H_t \left(\sum_{z \in S} \nabla \ell(w_t, z)\right)}_{U_2(S)} + O(\eta_t^3) U ( t ) ( S ) = U 1 ( S ) − η t z ∈ S ∑ ∇ ℓ ( w t , z val ) ⋅ ∇ ℓ ( w t , z ) + 2 1 U 2 ( S ) η t 2 ( z ∈ S ∑ ∇ ℓ ( w t , z ) ) T H t ( z ∈ S ∑ ∇ ℓ ( w t , z ) ) + O ( η t 3 ) 先给答案,一阶近似下的 In-Run Data Shapley 有闭式解:
ϕ z ( U ) ≈ ∑ t = 0 T − 1 ϕ z ( U 1 ( t ) ) \phi_z(U) \approx \sum_{t=0}^{T-1} \phi_z(U_1^{(t)}) ϕ z ( U ) ≈ t = 0 ∑ T − 1 ϕ z ( U 1 ( t ) ) 其中对每一步 t = 0 , … , T − 1 t = 0, \ldots, T-1 t = 0 , … , T − 1
ϕ z ( U 1 ( t ) ) = − η t ∇ ℓ ( w t , z val ) ⋅ ∇ ℓ ( w t , z ) \phi_z(U_1^{(t)}) = -\eta_t \; \nabla\ell(w_t, z^{\text{val}}) \cdot \nabla\ell(w_t, z) ϕ z ( U 1 ( t ) ) = − η t ∇ ℓ ( w t , z val ) ⋅ ∇ ℓ ( w t , z ) 二阶近似下的 In-Run Data Shapley 也有闭式解:
ϕ z ( U ) ≈ ∑ t = 0 T − 1 ( ϕ z ( U 1 ( t ) ) + 1 2 ϕ z ( U 2 ( t ) ) ) \phi_z(U) \approx \sum_{t=0}^{T-1} \left( \phi_z(U_1^{(t)}) + \frac{1}{2} \phi_z(U_2^{(t)}) \right) ϕ z ( U ) ≈ t = 0 ∑ T − 1 ( ϕ z ( U 1 ( t ) ) + 2 1 ϕ z ( U 2 ( t ) ) ) 其中对每一步 t = 0 , … , T − 1 t = 0, \ldots, T-1 t = 0 , … , T − 1
ϕ z ( U 1 ( t ) ) + 1 2 ϕ z ( U 2 ( t ) ) = − η t ∇ ℓ ( w t , z val ) ⋅ ∇ ℓ ( w t , z ) + η t 2 2 ∇ ℓ ( w t , z ) ⊤ H t ( ∑ z j ∈ batch ∇ ℓ ( w t , z j ) ) \phi_z(U_1^{(t)}) + \frac{1}{2} \phi_z(U_2^{(t)}) = -\eta_t \; \nabla\ell(w_t, z^{\text{val}}) \cdot \nabla\ell(w_t, z) + \frac{\eta_t^2}{2} \; \nabla\ell(w_t, z)^\top H_t \left( \sum_{z_j \in \text{batch}} \nabla\ell(w_t, z_j) \right) ϕ z ( U 1 ( t ) ) + 2 1 ϕ z ( U 2 ( t ) ) = − η t ∇ ℓ ( w t , z val ) ⋅ ∇ ℓ ( w t , z ) + 2 η t 2 ∇ ℓ ( w t , z ) ⊤ H t z j ∈ batch ∑ ∇ ℓ ( w t , z j ) 第一项衡量训练样本 z z z z z z
一阶近似及计算技巧#
对于一阶 In-run Data Shapley,U 1 U_1 U 1
U 1 ( S ) = ∑ z ∈ S f ( z ) U_1(S) = \sum_{z \in S} f(z) U 1 ( S ) = z ∈ S ∑ f ( z ) 即集合的效用等于集合中每个样本各自贡献的简单加和 ,每个 f ( z ) f(z) f ( z ) z z z
则有:
U 1 ( S ∪ { z } ) − U 1 ( S ) = ( f ( z ) + ∑ z i ∈ S f ( z i ) ) − ∑ z i ∈ S f ( z i ) = f ( z ) U_1(S \cup \{z\}) - U_1(S) = \left(f(z) + \sum_{z_i \in S} f(z_i)\right) - \sum_{z_i \in S} f(z_i) = f(z) U 1 ( S ∪ { z }) − U 1 ( S ) = ( f ( z ) + z i ∈ S ∑ f ( z i ) ) − z i ∈ S ∑ f ( z i ) = f ( z ) 那么,代入 Shapley 值定义可得:
ϕ z ( U 1 ) = 1 N ∑ k = 1 N ( N − 1 k − 1 ) − 1 ∑ S ⊆ D − z , ∣ S ∣ = k − 1 f ( z ) = f ( z ) ⋅ 1 N ∑ k = 1 N ( N − 1 k − 1 ) − 1 ( N − 1 k − 1 ) = f ( z ) \phi_z(U_1) = \frac{1}{N} \sum_{k=1}^N \binom{N-1}{k-1}^{-1} \sum_{S \subseteq D_{-z}, |S|=k-1} f(z) = f(z) \cdot \frac{1}{N} \sum_{k=1}^N \binom{N-1}{k-1}^{-1} \binom{N-1}{k-1} = f(z) ϕ z ( U 1 ) = N 1 k = 1 ∑ N ( k − 1 N − 1 ) − 1 S ⊆ D − z , ∣ S ∣ = k − 1 ∑ f ( z ) = f ( z ) ⋅ N 1 k = 1 ∑ N ( k − 1 N − 1 ) − 1 ( k − 1 N − 1 ) = f ( z ) 因此:
ϕ z ( U 1 ) = − η t ∇ ℓ ( w t , z val ) ⋅ ∇ ℓ ( w t , z ) \phi_z(U_1) = -\eta_t \nabla\ell(w_t, z^{\text{val}}) \cdot \nabla\ell(w_t, z) ϕ z ( U 1 ) = − η t ∇ ℓ ( w t , z val ) ⋅ ∇ ℓ ( w t , z ) 其中 ∇ ℓ ( w t , z val ) \nabla\ell(w_t, z^{\text{val}}) ∇ ℓ ( w t , z val ) ∇ ℓ ( w t , z ) \nabla\ell(w_t, z) ∇ ℓ ( w t , z )
注意上式只用了验证集一个点用于计算shapley值,但由于可加性,因此可以轻易拓展到整个验证集。
个人理解#
可以这样理解:验证梯度是验证点想让模型向哪个方向走,训练梯度是训练样本想让模型往哪个方向走,两个方向一致说明z z z
对于一阶shapley值的相对大小,将 s z : = ϕ z ( U 1 ) = − η t ∇ ℓ ( z val ) ⋅ ∇ ℓ ( z ) s_z := \phi_z(U_1) = -\eta_t \nabla\ell(z^{\text{val}}) \cdot \nabla\ell(z) s z := ϕ z ( U 1 ) = − η t ∇ ℓ ( z val ) ⋅ ∇ ℓ ( z )
s z = − η t ∥ ∇ ℓ ( z val ) ∥ ∥ ∇ ℓ ( z ) ∥ cos θ s_z = -\eta_t \; \|\nabla\ell(z^{\text{val}})\| \; \|\nabla\ell(z)\| \; \cos\theta s z = − η t ∥∇ ℓ ( z val ) ∥ ∥∇ ℓ ( z ) ∥ cos θ 由于 ∇ ℓ ( z val ) \nabla\ell(z^{\text{val}}) ∇ ℓ ( z val ) η t \eta_t η t
因素 含义 对得分的影响 ∥ ∇ ℓ ( z ) ∥ \|\nabla\ell(z)\| ∥∇ ℓ ( z ) ∥ 该样本在当前参数处的”陡峭程度”——模型对该样本的预测”自信”还是”不自信” 范数大 → 该样本的单步影响大(无论正负) cos θ \cos\theta cos θ 该样本降低自身损失的方向与降低验证损失的方向是否一致 越一致 → 正贡献越大;越相反 → 负贡献越大
更具象的类比:把模型训练想象成众人划船:
验证梯度 = 船想去的方向(目标方向)每个样本的梯度 = 每个人划船的方向和力气∥ ∇ ℓ ( z ) ∥ \|\nabla\ell(z)\| ∥∇ ℓ ( z ) ∥ cos θ \cos\theta cos θ
相对贡献的理解:
两个人都在正向划(正贡献),但一个人划得更用力(梯度范数大),他的贡献就更大
两个人用同样的力气,但一个人划的方向和船头方向更对齐(cos θ \cos\theta cos θ
以上分析同时可以看出:验证集的质量非常重要。
计算技巧:Ghost Dot-Product#
对线性层 s = a W \mathbf{s} = \mathbf{a}\mathbf{W} s = aW W ∈ R d 1 × d 2 \mathbf{W} \in \mathbb{R}^{d_1 \times d_2} W ∈ R d 1 × d 2
∂ ℓ ( i ) ∂ W = ∂ ℓ ( i ) ∂ s ( i ) ⊗ a ( i ) = b ( i ) ⊗ a ( i ) \frac{\partial \ell^{(i)}}{\partial \mathbf{W}} = \frac{\partial \ell^{(i)}}{\partial \mathbf{s}^{(i)}} \otimes \mathbf{a}^{(i)} = \mathbf{b}^{(i)} \otimes \mathbf{a}^{(i)} ∂ W ∂ ℓ ( i ) = ∂ s ( i ) ∂ ℓ ( i ) ⊗ a ( i ) = b ( i ) ⊗ a ( i )
其中:
a ( i ) ∈ R d 1 \mathbf{a}^{(i)} \in \mathbb{R}^{d_1} a ( i ) ∈ R d 1 i i i 输入激活值 (前向传播时已计算)b ( i ) ∈ R d 2 \mathbf{b}^{(i)} \in \mathbb{R}^{d_2} b ( i ) ∈ R d 2 i i i 输出梯度 (反向传播时已计算)
注意到:ℓ = ∑ j = 1 B ℓ ( j ) \ell = \sum_{j=1}^B \ell^{(j)} ℓ = ∑ j = 1 B ℓ ( j ) 对 ℓ \ell ℓ ℓ ( i ) \ell^{(i)} ℓ ( i ) s ( i ) \mathbf{s}^{(i)} s ( i ) s ( i ) \mathbf{s}^{(i)} s ( i ) :
∂ ℓ ( i ) ∂ s ( i ) = ∂ ℓ ∂ s ( i ) \frac{\partial \ell^{(i)}}{\partial \mathbf{s}^{(i)}} = \frac{\partial \ell}{\partial \mathbf{s}^{(i)}} ∂ s ( i ) ∂ ℓ ( i ) = ∂ s ( i ) ∂ ℓ
这意味着 ( a ( i ) , b ( i ) ) (\mathbf{a}^{(i)}, \mathbf{b}^{(i)}) ( a ( i ) , b ( i ) ) 全部自然可得 ,无需额外计算。
因此对于两个样本梯度点积可以这样计算:
∂ ℓ ( 1 ) ∂ W ⊙ ∂ ℓ ( 2 ) ∂ W = ( b ( 1 ) ⊗ a ( 1 ) ) ⊙ ( b ( 2 ) ⊗ a ( 2 ) ) = ( ( a ( 1 ) ) T a ( 2 ) ) ( ( b ( 1 ) ) T b ( 2 ) ) \begin{aligned}
\frac{\partial \ell^{(1)}}{\partial \mathbf{W}} \odot \frac{\partial \ell^{(2)}}{\partial \mathbf{W}}
&= (\mathbf{b}^{(1)} \otimes \mathbf{a}^{(1)}) \odot (\mathbf{b}^{(2)} \otimes \mathbf{a}^{(2)}) \\
&= ((\mathbf{a}^{(1)})^T \mathbf{a}^{(2)})((\mathbf{b}^{(1)})^T \mathbf{b}^{(2)})
\end{aligned} ∂ W ∂ ℓ ( 1 ) ⊙ ∂ W ∂ ℓ ( 2 ) = ( b ( 1 ) ⊗ a ( 1 ) ) ⊙ ( b ( 2 ) ⊗ a ( 2 ) ) = (( a ( 1 ) ) T a ( 2 ) ) (( b ( 1 ) ) T b ( 2 ) ) 具体流程如下:
常规训练的一次迭代: 输入: batch = {z_1, ..., z_B}, 验证样本 z_val -------------------------------------------------------------------------------- 1. 前向传播:计算 L_total = ΣL(z_i) + L(z_val) └── 保存每层激活值 a^{(i)}(前向时自然得到) 2. 反向传播:计算 ∂L_total/∂w(用于参数更新) └── 保存每层输出梯度 b^{(i)}(反向时自然得到) 3. Ghost 计算: ┌────────────────────────────────────────────┐ │ 对每一层: │ │ for each z_i in batch: │ │ dot_i = (a^{(i)}·a^{(val)}) │ ← 激活值内积 │ × (b^{(i)}·b^{(val)}) │ ← 输出梯度内积 │ │ │ φ_i = -η_t × Σ_layers dot_i │ ← 对全模型加和 └────────────────────────────────────────────┘ 4. 参数更新:w ← w - η_t · ∂L_total/∂w -------------------------------------------------------------------------------- 输出: 每个样本的 Shapley 分数 φ_i, 更新后的参数 w_{t+1} plaintext
code
二阶近似 及 高效计算#
ϕ z ( U ( t ) ) = ϕ z ( U 1 ) + 1 2 ϕ z ( U 2 ) = − η t ∇ ℓ ( w t , z val ) ⋅ ∇ ℓ ( w t , z ) + η t 2 2 ∇ ℓ ( w t , z ) T H t ( ∑ z j ∈ batch ∇ ℓ ( w t , z j ) ) \phi_z(U^{(t)}) = \phi_z(U_1) + \frac{1}{2}\phi_z(U_2) = -\eta_t \nabla\ell(w_t, z^{\text{val}}) \cdot \nabla\ell(w_t, z) + \frac{\eta_t^2}{2} \nabla\ell(w_t, z)^T H_t \left(\sum_{z_j \in \text{batch}} \nabla\ell(w_t, z_j)\right) ϕ z ( U ( t ) ) = ϕ z ( U 1 ) + 2 1 ϕ z ( U 2 ) = − η t ∇ ℓ ( w t , z val ) ⋅ ∇ ℓ ( w t , z ) + 2 η t 2 ∇ ℓ ( w t , z ) T H t z j ∈ batch ∑ ∇ ℓ ( w t , z j ) 一阶项已经证明;对于二阶项证明如下:
记 x j : = ∇ ℓ ( w t , z j ) x_j := \nabla\ell(w_t, z_j) x j := ∇ ℓ ( w t , z j ) x ~ : = ∇ ℓ ( w t , z ) \tilde{x} := \nabla\ell(w_t, z) x ~ := ∇ ℓ ( w t , z ) H : = H t H := H_t H := H t
则 U 2 ( S ) = η t 2 ( ∑ z j ∈ S x j ) T H ( ∑ z j ∈ S x j ) U_2(S) = \eta_t^2 \left(\sum_{z_j \in S} x_j\right)^T H \left(\sum_{z_j \in S} x_j\right) U 2 ( S ) = η t 2 ( ∑ z j ∈ S x j ) T H ( ∑ z j ∈ S x j )
(a) 先求边际贡献。对任意 S ⊆ batch ∖ { z } S \subseteq \text{batch} \setminus \{z\} S ⊆ batch ∖ { z }
U 2 ( S ∪ { z } ) − U 2 ( S ) = η t 2 ( x ~ + ∑ j ∈ S x j ) T H ( x ~ + ∑ j ∈ S x j ) − η t 2 ( ∑ j ∈ S x j ) T H ( ∑ j ∈ S x j ) = η t 2 ( 2 x ~ T H ( ∑ j ∈ S x j ) + x ~ T H x ~ ) \begin{aligned}
U_2(S\cup\{z\}) - U_2(S) &= \eta_t^2 \left(\tilde{x} + \sum_{j\in S} x_j\right)^T H \left(\tilde{x} + \sum_{j\in S} x_j\right) - \eta_t^2 \left(\sum_{j\in S} x_j\right)^T H \left(\sum_{j\in S} x_j\right) \\
&= \eta_t^2 \left( 2\tilde{x}^T H \left(\sum_{j\in S} x_j\right) + \tilde{x}^T H \tilde{x} \right)
\end{aligned} U 2 ( S ∪ { z }) − U 2 ( S ) = η t 2 x ~ + j ∈ S ∑ x j T H x ~ + j ∈ S ∑ x j − η t 2 j ∈ S ∑ x j T H j ∈ S ∑ x j = η t 2 2 x ~ T H j ∈ S ∑ x j + x ~ T H x ~ 这里展开时注意 ( ∑ S x j ) T H x ~ = x ~ T H ( ∑ S x j ) \left(\sum_{S} x_j\right)^T H \tilde{x} = \tilde{x}^T H \left(\sum_{S} x_j\right) ( ∑ S x j ) T H x ~ = x ~ T H ( ∑ S x j ) 2 x ~ T H ∑ S x j 2\tilde{x}^T H \sum_{S} x_j 2 x ~ T H ∑ S x j
(b) 代入 Shapley 值定义。令 n = ∣ batch ∣ n = |\text{batch}| n = ∣ batch ∣
ϕ z ( U 2 ) = η t 2 ⋅ 1 n ∑ k = 1 n ( n − 1 k − 1 ) − 1 ∑ S ⊆ batch ∖ { z } , ∣ S ∣ = k − 1 [ 2 x ~ T H ∑ j ∈ S x j + x ~ T H x ~ ] \phi_z(U_2) = \eta_t^2 \cdot \frac{1}{n} \sum_{k=1}^n \binom{n-1}{k-1}^{-1} \sum_{S \subseteq \text{batch}\setminus\{z\}, |S|=k-1} \left[ 2\tilde{x}^T H \sum_{j\in S} x_j + \tilde{x}^T H \tilde{x} \right] ϕ z ( U 2 ) = η t 2 ⋅ n 1 k = 1 ∑ n ( k − 1 n − 1 ) − 1 S ⊆ batch ∖ { z } , ∣ S ∣ = k − 1 ∑ 2 x ~ T H j ∈ S ∑ x j + x ~ T H x ~ 把常数项 x ~ T H x ~ \tilde{x}^T H \tilde{x} x ~ T H x ~ k k k k − 1 k-1 k − 1 S S S ( n − 1 k − 1 ) \binom{n-1}{k-1} ( k − 1 n − 1 )
1 n ∑ k = 1 n ( n − 1 k − 1 ) − 1 ( n − 1 k − 1 ) x ~ T H x ~ = 1 n ∑ k = 1 n x ~ T H x ~ = x ~ T H x ~ \frac{1}{n} \sum_{k=1}^n \binom{n-1}{k-1}^{-1} \binom{n-1}{k-1} \tilde{x}^T H \tilde{x} = \frac{1}{n} \sum_{k=1}^n \tilde{x}^T H \tilde{x} = \tilde{x}^T H \tilde{x} n 1 k = 1 ∑ n ( k − 1 n − 1 ) − 1 ( k − 1 n − 1 ) x ~ T H x ~ = n 1 k = 1 ∑ n x ~ T H x ~ = x ~ T H x ~ 对于含 ∑ S x j \sum_{S} x_j ∑ S x j z j ( j ≠ z ) z_j (j \neq z) z j ( j = z ) S S S k − 1 k-1 k − 1 z j z_j z j S S S ( n − 2 k − 2 ) \binom{n-2}{k-2} ( k − 2 n − 2 ) z z z z j z_j z j n − 2 n-2 n − 2 k − 2 k-2 k − 2
1 n ∑ k = 1 n ( n − 1 k − 1 ) − 1 ∑ S , ∣ S ∣ = k − 1 2 x ~ T H ∑ j ∈ S x j = 2 n ∑ k = 2 n ( n − 1 k − 1 ) − 1 ( n − 2 k − 2 ) x ~ T H ( ∑ z j ∈ batch ∖ { z } x j ) = 2 n ∑ k = 2 n k − 1 n − 1 ⋅ x ~ T H ( ∑ z j ∈ batch ∖ { z } x j ) = x ~ T H ( ∑ z j ∈ batch ∖ { z } x j ) \begin{aligned}
&\frac{1}{n} \sum_{k=1}^n \binom{n-1}{k-1}^{-1} \sum_{S, |S|=k-1} 2\tilde{x}^T H \sum_{j\in S} x_j \\
&= \frac{2}{n} \sum_{k=2}^n \binom{n-1}{k-1}^{-1} \binom{n-2}{k-2} \tilde{x}^T H \left(\sum_{z_j \in \text{batch}\setminus\{z\}} x_j\right) \\
&= \frac{2}{n} \sum_{k=2}^n \frac{k-1}{n-1} \cdot \tilde{x}^T H \left(\sum_{z_j \in \text{batch}\setminus\{z\}} x_j\right) \\
&= \tilde{x}^T H \left(\sum_{z_j \in \text{batch}\setminus\{z\}} x_j\right)
\end{aligned} n 1 k = 1 ∑ n ( k − 1 n − 1 ) − 1 S , ∣ S ∣ = k − 1 ∑ 2 x ~ T H j ∈ S ∑ x j = n 2 k = 2 ∑ n ( k − 1 n − 1 ) − 1 ( k − 2 n − 2 ) x ~ T H z j ∈ batch ∖ { z } ∑ x j = n 2 k = 2 ∑ n n − 1 k − 1 ⋅ x ~ T H z j ∈ batch ∖ { z } ∑ x j = x ~ T H z j ∈ batch ∖ { z } ∑ x j 其中 ( n − 2 k − 2 ) / ( n − 1 k − 1 ) = k − 1 n − 1 \binom{n-2}{k-2}/\binom{n-1}{k-1} = \frac{k-1}{n-1} ( k − 2 n − 2 ) / ( k − 1 n − 1 ) = n − 1 k − 1 2 n ∑ k = 2 n k − 1 n − 1 = 2 n ⋅ n ( n − 1 ) 2 ( n − 1 ) = 1 \frac{2}{n}\sum_{k=2}^n \frac{k-1}{n-1} = \frac{2}{n} \cdot \frac{n(n-1)}{2(n-1)} = 1 n 2 ∑ k = 2 n n − 1 k − 1 = n 2 ⋅ 2 ( n − 1 ) n ( n − 1 ) = 1
(c) 合并两项得到:
ϕ z ( U 2 ) = η t 2 ( x ~ T H x ~ + x ~ T H ( ∑ z j ∈ batch ∖ { z } x j ) ) = η t 2 x ~ T H ( ∑ z j ∈ batch x j ) \phi_z(U_2) = \eta_t^2 \left( \tilde{x}^T H \tilde{x} + \tilde{x}^T H \left(\sum_{z_j \in \text{batch}\setminus\{z\}} x_j\right) \right) = \eta_t^2 \tilde{x}^T H \left(\sum_{z_j \in \text{batch}} x_j\right) ϕ z ( U 2 ) = η t 2 x ~ T H x ~ + x ~ T H z j ∈ batch ∖ { z } ∑ x j = η t 2 x ~ T H z j ∈ batch ∑ x j 高效计算#
我没看懂,记录如下
二阶项需要计算梯度-Hessian-梯度乘积:
ϕ z ( U 2 ) = η t 2 ⋅ ∇ ℓ ( z ) T ⋅ H ⋅ ( ∑ z j ∈ batch ∇ ℓ ( z j ) ) \phi_z(U_2) = \eta_t^2 \cdot \nabla\ell(z)^T \cdot H \cdot \left(\sum_{z_j \in \text{batch}} \nabla\ell(z_j)\right) ϕ z ( U 2 ) = η t 2 ⋅ ∇ ℓ ( z ) T ⋅ H ⋅ ( ∑ z j ∈ batch ∇ ℓ ( z j ) )
通过H ⋅ v = ∇ ( ∇ L ⋅ v ) H \cdot v = \nabla(\nabla L \cdot v) H ⋅ v = ∇ ( ∇ L ⋅ v ) H H H v v v
具体流程:
第一次反向传播 (与一阶共享,1 次 backprop):
对 ∑ z ∈ batch ℓ ( z ) + ℓ ( z val ) 做反向传播 \text{对 } \sum_{z \in \text{batch}} \ell(z) + \ell(z^{\text{val}}) \text{ 做反向传播} 对 z ∈ batch ∑ ℓ ( z ) + ℓ ( z val ) 做反向传播 得到所有样本在各层的激活值 a l ( i ) \mathbf{a}_l^{(i)} a l ( i ) b l ( i ) \mathbf{b}_l^{(i)} b l ( i )
构造标量 s s s
s = ∇ ℓ ( z val ) ⋅ ( ∑ j ∇ ℓ ( z j ) ) = ∑ l ( ( a l val ) T ∑ j a l ( j ) ) ( ( b l val ) T ∑ j b l ( j ) ) s = \nabla\ell(z^{\text{val}}) \cdot \left(\sum_{j} \nabla\ell(z_j)\right) = \sum_l ((\mathbf{a}_l^{\text{val}})^T \sum_j \mathbf{a}_l^{(j)}) \; ((\mathbf{b}_l^{\text{val}})^T \sum_j \mathbf{b}_l^{(j)}) s = ∇ ℓ ( z val ) ⋅ ( ∑ j ∇ ℓ ( z j ) ) = ∑ l (( a l val ) T ∑ j a l ( j ) ) (( b l val ) T ∑ j b l ( j ) )
第二次反向传播 (1 次额外 backprop):
h : = ∂ s ∂ w = H ⋅ ( ∑ j ∇ ℓ ( z j ) ) h := \frac{\partial s}{\partial w} = H \cdot \left(\sum_j \nabla\ell(z_j)\right) h := ∂ w ∂ s = H ⋅ ( ∑ j ∇ ℓ ( z j ) )
反向传播自动计算出这个 Hessian-向量积,全程不构造 Hessian 矩阵。
对每个样本用 Ghost Dot-Product 算 ϕ z ( U 2 ) \phi_z(U_2) ϕ z ( U 2 )
ϕ z i ( U 2 ) = η t 2 ⋅ ∇ ℓ ( z i ) ⋅ h \phi_{z_i}(U_2) = \eta_t^2 \cdot \nabla\ell(z_i) \cdot h ϕ z i ( U 2 ) = η t 2 ⋅ ∇ ℓ ( z i ) ⋅ h
同样用 Ghost 公式逐层计算:
∇ ℓ ( z i ) ⋅ h = ∑ l ( ( a l ( i ) ) T h l a ) ( ( b l ( i ) ) T h l b ) \nabla\ell(z_i) \cdot h = \sum_l ((\mathbf{a}_l^{(i)})^T \mathbf{h}_l^a) \; ((\mathbf{b}_l^{(i)})^T \mathbf{h}_l^b) ∇ ℓ ( z i ) ⋅ h = ∑ l (( a l ( i ) ) T h l a ) (( b l ( i ) ) T h l b )
其中 h l a , h l b \mathbf{h}_l^a, \mathbf{h}_l^b h l a , h l b h h h
局限性#
验证数据必须在训练前可用
二阶改进幅度有限
只能用于SDG优化器,因为 Adam 的参数更新不是梯度的线性函数
数据清洗 :一次训练后排序移除 Shapley 值最低的样本
数据配比 :
Shapley 值衡量的是”贡献”而非”难度”,需要注意高 Shapley 值的样本往往是”难但有价值”的样本,而不是”简单”样本。 ,同时样本在模型训练的不同阶段会贡献会不同。
一些思路:
追踪每个样本的 Shapley 值随训练步数的变化:
早期高、后期低 → 已学会的基础样本逐渐从负转正 → “可教”的样本,适合在当前阶段加入始终为负 → 问题数据,排除后期才变高 → 适合后期加入的”进阶”样本